In our previous post, Product Classification Techniques in eCommerce, we explored how artificial intelligence, specifically Large Language Models (LLMs), can be effectively used to classify products within evolving eCommerce environments. This sparked a lot of interest and questions from you, our readers, prompting me to write this follow-up to address some of the most common queries. Let’s dive deeper into how product classification can be fine-tuned to accommodate multiple languages, inconsistent terminology, and format disparities across various data sources.
What happens when you have product listings in multiple languages?
One of the most frequent questions was about managing product classification when an eCommerce site has product listings in multiple languages. This challenge can significantly impact how products are categorized and presented to different audiences, directly affecting conversions, searchability, and user experience.
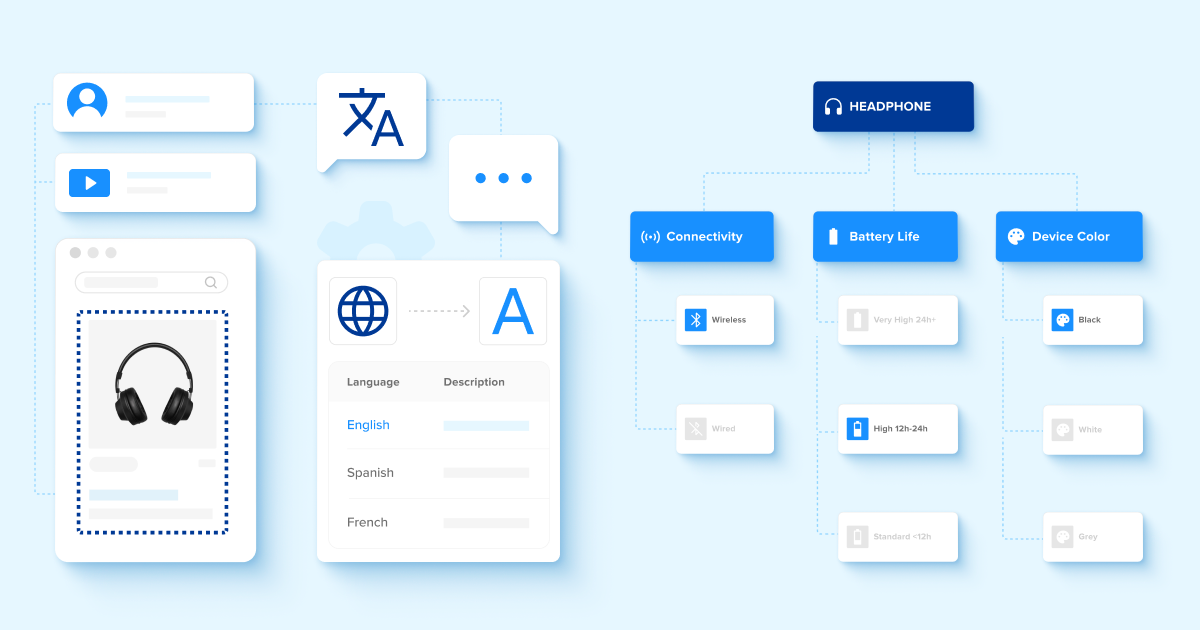
To make this clearer, let’s look at the role of LLMs in multilingual product classification. The core principle remains the same as we discussed in our initial post: LLMs leverage context-aware natural language processing (NLP) to understand not just the literal translation of words, but the context, nuances, and intended meaning behind them. This allows them to categorize products correctly, even when listings are in different languages.
Example 1: Translating Multilingual Product Listings
Consider the product “bamboo fiber shirt,” which would translate to “camiseta de fibra de bambú” in Spanish. While this is a correct literal translation, natural language processing enables us to go a step further by understanding that “fibra de bambú” is associated with sustainable and eco-friendly clothing. This enables the system to categorize the product in both English and Spanish as part of an eco-friendly or sustainable apparel category, which enhances the search and shopping experience for users interested in such products.
Example 2: Regional Language Variations
Let’s take the word “shoes.” In Spain, the word “zapatos” is commonly used, whereas in Latin America, “calzados” is more frequent. Even with these regional variations, LLMs are capable of correctly classifying these as “footwear” or more specifically into subcategories like “casual shoes” or “athletic shoes” by understanding the broader context and terminology used in that particular region.
But the challenge doesn’t stop at simple translations or regional variations. Contextual differences in language can create even more complex situations. In Spain, the word “coche” refers to a car, but in some Latin American countries, “coche” is used to refer to a baby stroller. In this case, natural language processing leverages contextual information (e.g., product descriptions and accompanying attributes) to ensure the item is categorized correctly, whether it’s a car in one country or a stroller in another.
How do you manage so many different sites and sources?
Many of you raised concerns about integrating product data from multiple sites and sources, each with different terminology, language variations, and format disparities. While this can seem overwhelming, the root challenges can be distilled into a few key areas, which LLMs are particularly adept at resolving.
Inconsistent Terminology
Inconsistent terminology is a common challenge in product categorization. For example, “T-shirt,” “tee,” and “top” might be used interchangeably across different eCommerce sites, but they all refer to the same type of clothing. LLMs use semantic analysis to recognize these variations and understand that, despite the different terms, they should all be classified under the same category of clothing.
How is this done?
LLMs achieve this by training on vast amounts of diverse data. They learn to associate different words or phrases with the same underlying concept by evaluating their context. For instance, if an LLM has seen the words “tee” and “T-shirt” used in similar contexts repeatedly—paired with descriptions or images of the same product type—it learns to treat these terms as synonymous when categorizing items. This ensures consistent classification, even when product data comes from disparate sources using different terminology.
Language Variations
Language variations, as discussed in the previous section, involve not only direct translations but also regional dialects and specific terminology. As highlighted above, the same product might be referred to by different names across regions, and natural language processing can process these variations contextually to ensure accurate classification regardless of the language.
Format Disparities
A more technical but equally important challenge is format disparities. Product data can come from multiple sources, often structured in different ways. For instance, one eCommerce site may have detailed specifications in neatly organized tables, while another may use unstructured text with inconsistent formatting for product descriptions, reviews, or marketing materials.
Example: Handling Format Disparities in eCommerce
Let’s say one site lists a “100% cotton T-shirt” with an organized table showing attributes like size, color, and material. Another site might simply mention “cotton tee” within a block of unstructured text. LLMs can parse both formats—extracting key information from the unstructured text just as effectively as it reads the structured table.
Challenges
The challenge here lies in consolidating and enriching the data from these different formats to provide a seamless and enriched product listing. Current approaches typically rely on manual processing, where human operators standardize data fields or implement basic rules to make the information consistent across sources. This process, however, is labor-intensive and error-prone.
LLMs to the Rescue
LLMs can automatically extract relevant attributes—like material, size, and even style—from unstructured descriptions and cross-reference this with data from structured fields in other sources. By doing so, they not only enrich the data but also verify the accuracy of product listings. This allows for more robust product cataloging, where the most important attributes are highlighted for users, leading to better categorization and search results.
Looking Ahead
In the next post, I plan to delve into another critical topic: similarity. We’ll explore how LLMs use similarity not only to improve like-matching but also to offer competitive advantages in product recommendations and customer personalization.
In the meantime, feel free to continue sending your questions! I hope this follow-up has clarified some of the key challenges and solutions around multilingual product classification, terminology consistency, and format disparities. Stay tuned for more insights!
Want to learn more? eCommerce leaders are invited to join us for a 30-minute working session to explore practical applications of ChatGPT in product classification. Attendees will gain hands-on experience with classifying their own products and how to optimize prompts to test and refine their strategies.
Register your interest for a September session below.